Transformer
Components
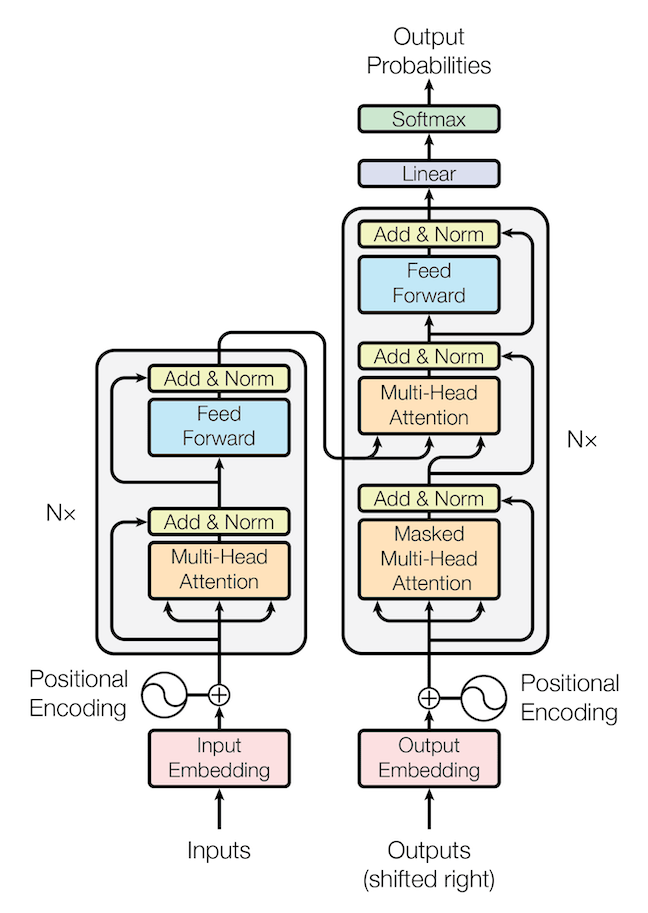
1. Tokenization
Converts words into tokens using a specific tokenizer.
2. Embedding
2.1 Input/Output embedding
- Converts tokens into high dimensional vectors using a fixed representation learnt through training.
- Each token occupies a unique location, related tokens are located close to each others.
2.2 Positional encoding
- Input/output tokens are processed in parallel.
- Adds a positional encoding to each token embeddings to preserve the information on word orders.
3. Attention

- Attention layer analyzes the relationships between different tokens in the sequence in parallel to capture the contextual dependencies.
- Multi-head attention layer combines multiple attention layers (typically 12-100) together to train and run in parallel. With randomly initialized weights, different attentions will learn different aspects of the languages.
- Self attention has Q, K, V as the same before projection. Cross attention has K, V as the same before projection, Q as the different.
4. Feed-Forward
- Takes a concatenation of the multi-head attention layer outputs to predict the probability of all tokens.
- Normalizes output as probabilities using softmax.
5. Encoder
- Stacks of a multi-head attention layer (self-attention) followed by a feed forward layer on input embeddings.
- Creates a deep representation of the structure and meaning of the input sequence.
6. Decoder
- Stacks of two multi-head attention layers (self-attention + cross-attention) followed by a feed forward layer on output embeddings and encoder outputs.
- Create a prediction of outputs probabilities.
Functions
-
A starter sequence token is added to the input of the decoder.
-
Triggers the decoder to predict the next token based on contextual understandings of generated output tokens (self-attention) and input tokens (cross-attention).
-
Passes the output token back to the input of decoder to trigger the generation of the next tokenm until the model predicts an end-of-sequence token.
References
Generative AI Engineering
Workflow
- Prompt(inputs) -> Model -> Prediction(outputs)
Prompt Engineering
- Prepends content of inputs to direct the model to provide the desired outputs.
- Zero/One/Few-shot inference: Provides zero/one/few completed examples in the prompt.
- In-context learning (ICL).
- Constaint is the model’s context window, the amount of memory avilable to use for prompt. Usually 5/6 shots are enough.
Generative Configuration
- Max number of new tokens. (Outputs are also limited by the terminating conditions)
- Greedy vs random sampling on output tokens.
- Top-K: Choose only from top k tokens with highest probability.
- Top-P: Choose only from top tokens that the total combined probability <= P.
- Temperature: A scaling factor applied within the final softmax layer that impacts the probability distribution of the next token.
- Low temperature results in reduced variability.
- High temperature results in increased randomnise. Probability is more evenly spread out throughout candidates, making outputs more creative.
Generative AI Lifecycle
Example 1
- Scope: Define the use case.
- Select: Choose an existing model or pretrain your own.
- Adapt and align: Prompt engineering / Fine tuning / Align with human feedback. Evaluate.
- Application integration: Optimize and deploy model for inference. Augment model and build LLM-powered applications.
Example 2
- Prep data.
- Select pre-trained model.
- Fine tuning with labeled data.
- Distillation with unlabled data.
- Service with distilled student model.
Large Language Model (LLM) pre-training and scaling
Variants of Transformers
| Architecture | Examples | Training Method | Training Objective | Best Use Cases |
|---|---|---|---|---|
| Encoder only (Autoencoding models) | BERT | Masked language modeling (MLM): input tokens are randomly masked; Bi-directional representation of input token: model have understanding of full context. | Predict the masked tokens in order to reconstruct the original sentence (Denoising objective) | Sentence classification tasks: sentiment analysis; Token-level tasks: named entity recognition word classification. |
| Decoder only (Autoregressive models) | GPT, BLOOM, PaLM, LLaMA | Causal language modeling (CLM): mask the input sequence and can only see the input tokens leading up to the token in question; Context is unidirectional. | Predict the next token based on the previous sequence of tokens. | Text generation. Show strong zero-short inference abilities, an can often perform a range of tasks well. |
| Encoder-decoder models | T5, MUM | Pre-train the encoder using span corruption, which makes random sequence of input tokens. Those mass sequences are then replaced with a unique sentinel token; Sentinel tokens are special tokens added to the vocabulary, but not correspond to any actual work from the input text; The decoder is then takes with reconstructing the mask token sequences auto-regressively. | Predict the original token (the output is the sentinel token followed by the predicted tokens). | Translation; Summarization; Question-answering. |
Challenges to train LLMs
Memory requirement
- Quantization.
- Partitions with multi-GPU strategies.
- Data parallel training (DDP).
- Model parallel training (ZeRO, Zero redundancy optimizer).
- Fully sharded data parallel.
Scaling laws of LLMs
- Power law relationship – training loss vs compute/dataset/model size.
- From DeepMind Chinchilla paper:
- Larger model might not lead to better results.
- Without sufficient training data, the models could be under-trained.
- Compute optimal # of tokens is 20x the # of model parameters.
- Chinchilla – 70B parameters. 1.4T training tokens.
Lab 1
Follow codelab to run all cells on dialogue summarization examples.
Transformer models and tokenizers from : Hugging face

Leave a comment