In-Context Learning v.s. Fine-Tuning
-
In-context learning:
- May not work for smaller models.
- Few-shot examples take up space in the limited context window.
-
Fine-tuning: Extends the training of the model to improve its ability to generate good completions for a specific task.
- Pre-training: Self-supervised learning. Train with vast amount of unstructured textual data. The input data is typically augmented or transformed in a way that creates pairs of related samples.
- Fine-tuning: Supervised learning. Updates the weights with a dataset of label examples. The labeled examples are prompt completion pairs.
Instruction Fine-Tuning
-
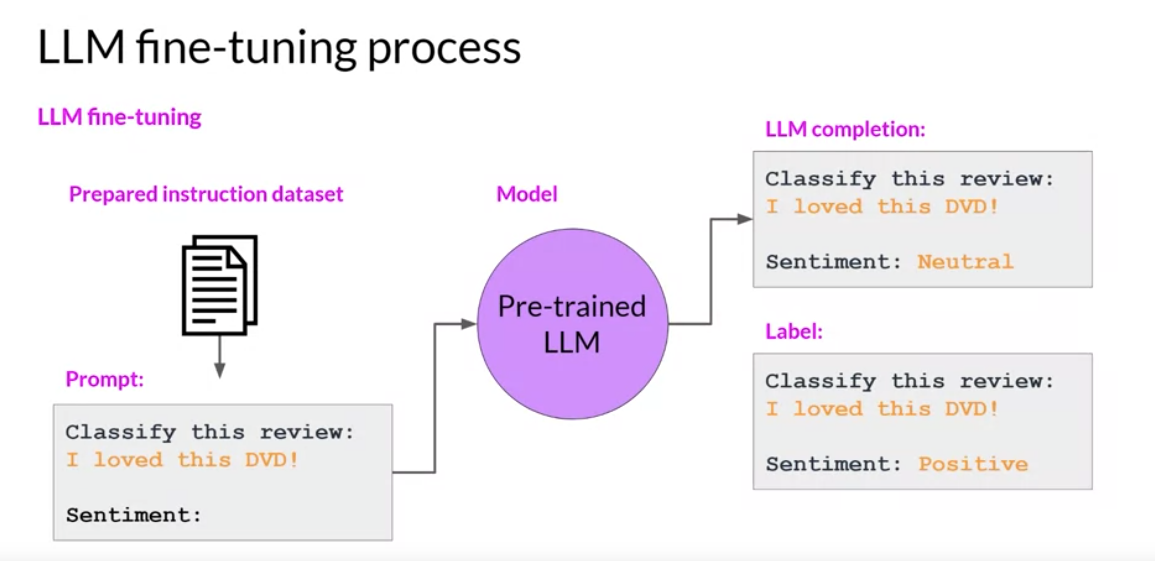
Instruction fine-tuning: trains the model using examples that demonstrate how it should respond to a specific instruction.
-
Instruction dataset -> Training (cross-entropy loss) -> Validation -> Test
-
Steps
- Step 1. Prepare training data for fine-tuning
- Format dataset as instructions: assemble prompt template libraries that can be used to take existing datasets and turn them into instruction prompt datasets for fine-tuning.
- Step 2. Training loop.
- Use standard cross-entropy loss function to update LLM weights based on the discrepancy between predictions and data labels.
- Step 1. Prepare training data for fine-tuning
-
Full fine-tuning: all of the model’s weights are updated. Requires enough memory and compute budge to store and process all the gradients, optimizer and other components that are being updated during training.
Single task Fine-Tuning
- Fast: Often 500-1000 examples can result in good performance, compared to billions of pieces of texts that the model saw during pre-training.
- Catastrophic forgetting: Full fine-tuning process modifies the original weights, leading to great performance on the single fine-tuned task, but degrade performance on other tasks.
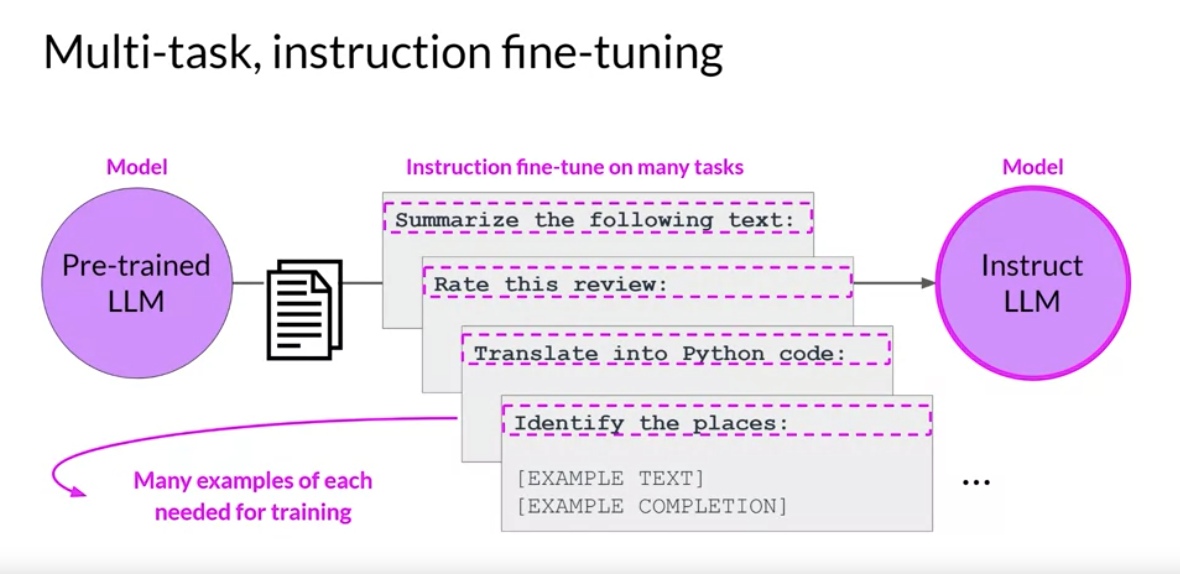
- Solution 1: Multi-task fine-tuning. It may require 50-100,000 examples across many tasks, and so will require more data and compute to train.
- Solution 2: Parameter efficient fine-tuning (PEFT). It is a set of techniques that preserves the original weights and trains only a small number of task-specific adapter layers and parameters.
- Solution 3: Regularization on weight upates.
- Also happens in unsupervised learning.
Multi-task Fine-Tuning
-
FLAN (Fine-tuned Language Net): A specific set of instructions used to perform instruction fine-tuning.
- FLAN-T5: General purpose instruct model. Fine-tuned on 473 datasets across 146k task categories.
- FLAN-PALM.
- Prompt template on dialogue and summary.
-
To help model perform better on specific tasks, one can perform multiple rounds of fine-tuning. Example:
- Assume an online merchant wants to deploy LLMs to summarize the custom service conversations with questions and action items.
- First, tune a pre-trained LLM with SAMSum for summarization tasks conversations – SAMSum dataset is mostly summary written by linguistics daily conversation between friends.
- Second, train the fine-tuned model on company specific tasks such as summarizing customer service chat.
Model Evaluation
Metrics
- Precision and Recall in Classification
- Precision: What proportion of positive identifications was actually correct?
- Recall: What proportion of actual positives was identified correctly?
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation): Primarily employed to asses the quality of automatically generated summaries.
- Compare summary with original to calculate recall.
- ROUGE-1: Number of words matched (Unigram).
- ROUGE-2: Number of word combinations matched (Bigram). Includes ordering.
- ROUGE-L: Longest common sequence matched.
- ROUGE-Hacking <-> ROUGE-Clipping: Clip matching to the maximum presence in ground truth to avoid repetition of generated words.
- BLEU(BiLigngual Evaluation Understudy): An algorithm designed to evaluate the quality of machine-translated text.
- Calculated using the average precision over multiple n-gram sizes.
- Checks how many n-grams in the machine-generated translation match those in the reference translation.
Benchmarks
- Common benchmarks: GLUE, SuperGLUE, MMU (Massive Multitask Language Understanding), BIG-bench, HELM (Holistic Evaluation of Language Models).
Parameter Efficient Fine-Tuning (PEFT)
- Fine-tuning
- High Memory Consumption (10x-12x)
- Trainable weights. Optimizer states. Gradients. Forward activations. Temporary memory.
- Overall Methods
- Frozen part weights.
- Frozen all weights. Add new trainable weights.
- Pros
- Save resources. Parameters/compute efficiency. Done on single GPU.
- Prone to catastrophic forgetting.
- Methods
- Selective: Select subset of initial LLM parameters to fine-tune. Fine-tune selected layers, individual parameters.
- Reparameterization: Reparameterize model weights using a low-rank representation.
- LoRA
- Additive
- Trainable compoenets
- Adapter layers
- Prompt tuning
- High Memory Consumption (10x-12x)
LoRA: Low Rank Adoption

-
Steps
- Train
- Freeze most of original weights.
- Inject 2 rank decomposition matrices.
- Train the weights of the smaller matrices.
- Inference
- Matrix multiply the low rank matrices.
- Add the result to the original weights.
- Train
-
Empirical study
- Where to apply: Applying LoRA to just self-attention layers of the model is often enough to fine-tune.
- Switch between different tasks for inference: Train different rank decomposition matrices for different tasks, and update weights before inference.
- How to choose the dimension of LoRA matrices: Ranks in range of 4-32 can provide a good trade-off between reducing trainable parameters and preserving performance.
- Optimizing the choice of rank is an ongoing area of research and best practices may evolve as more practitioners make uses of LoRA.
Prompt Tuning
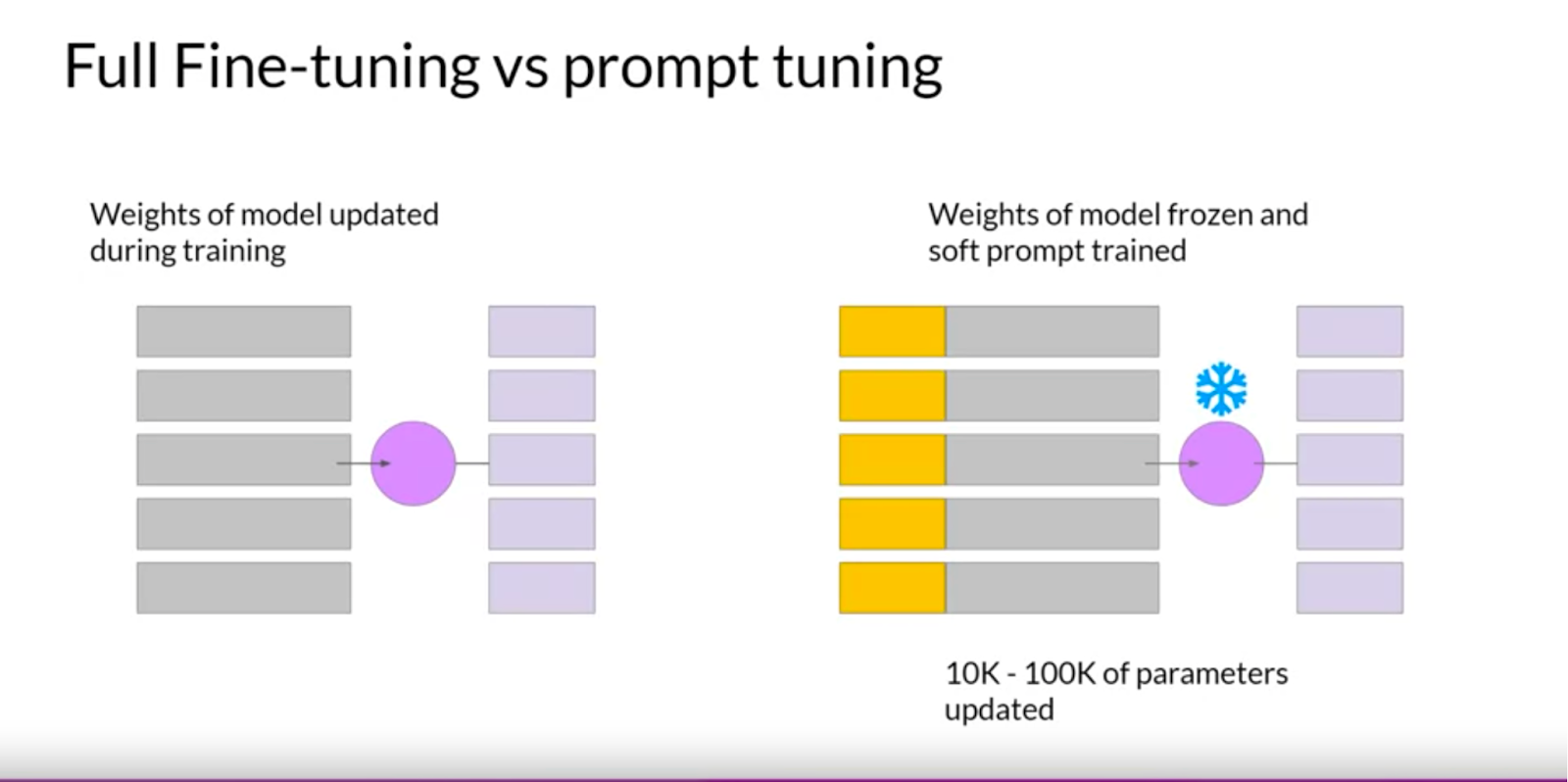
- Prompt Tuning vs Prompt Engineering
- Prompt Engineering: Help the model understand the nature of the task you are asking it to carry out and to generate better completion.
- Limitations: Require a lot of manual effort to write and try different prompts. Be limited by the length of context window. May still not achieve performance needed for task.
- Prompt Tuning: Add additional trainable tokens to your prompt and leave it up to the supervised learning process to determine their optimal values.
- Soft prompt: The set of trainable tokens in prompt tuning, which then gets prepended to embedding vectors that represent your input text.
- Soft prompt vectors has the same length as embedding vectors of language tokens.
- Embedding vector of soft prompt get updated instead of the weights.
- Including between 20-100 virtual tokens can be sufficient for good performance.
- Soft prompts are small on disk, so this kind of fine-tuning is extremely efficient and flexible.
- Intuition
- Tokens represents natural language are hard as they each correspond to a fixed location in the embedding vector space.
- Soft prompts are not fixed discrete word and can take any value in continuous vector space, which can be learnt during supervised learning.
- Risk: Interpretability of learned virtual tokens: The trained tokens don’t correspond to any known token, word, or phrase in vocabulary.
- Solution: The words closest to the soft prompt tokens have similar meanings, and can be used to help interpret the learned soft prompts.

Leave a comment