Reinforcement Learning with Human Feedback
- Purpose: Alignment of the model with human values. Making the model:
- More helpful.
- Not causing harm: Using toxic language in completions. Reply in combative and aggressive voices. Provide detailed information about dangerous topics.
- Less misinformation: Hallucinate, answer a question it doesn’t know confidently.
Reinforcement Learning
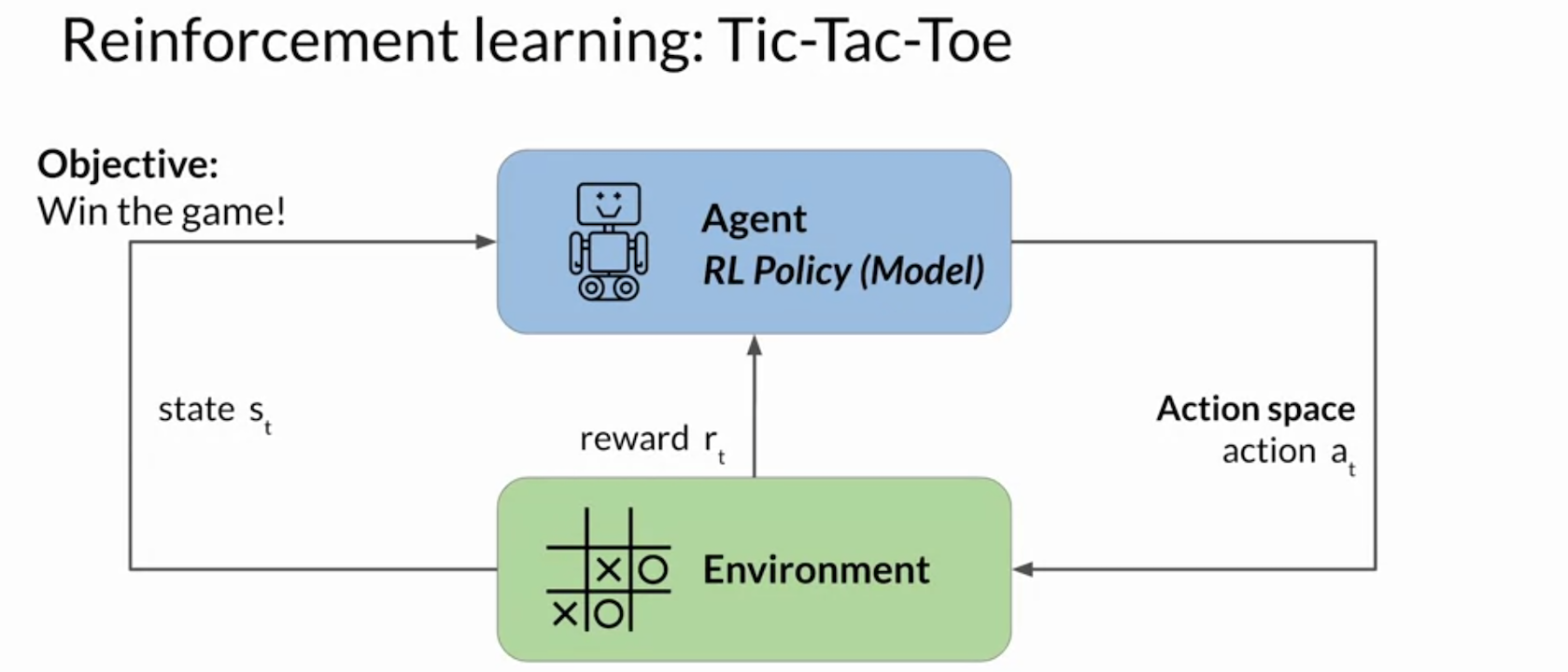
- Objective: Maximize reward received for actions.
- Policy: LLM itself.
- Environment: The context window. The space in which text can be entered via a prompt.
- State: Text in the context window.
- Action: Generating text.
- Reward: How closely the model output aligns with the human preferences.
- Rollout: The sequence pf states & actions in the process of fine-tuning.
Reward Model
A model to assess the alignment of a completion, to be used during RLHF training.
How to do RLHF
- Have human labelers rank completion on helpfulness, harm, etc.
- Convert rankings to pairwise training data.
- For example, less helpful completion using 0 as no reward and more helpful information using 1 as rewarded.
- Train reward model, the model returns a score on the alignment of the completion.
- We can use the logits before the probabilities output.
- Iteratively fine-tune the model on the dataset. Update LLM weights based on the rewards.
Reward hacking

- Problem: The model is biased towards reward model, and outputs aligned but not relevant results. Similar to overfitting.
- Solution: Add a regularize, a reference model that stays frozen. Adds a penalty term on their difference, for example the KL divergence.

Proximal Policy Optimization (PPO)
Phase 1. Calculate loss of value function

: Value function. Estimated future rewards.
: Known future total reward.
Phase 2. Calculate loss of policy function

 Model’s probability distribution over tokens.
Model’s probability distribution over tokens.
: Probabilities of next token on the updated LLM.
: Probabilities of next token on the initial LLM.
: Advantage term.
: Trust region with original and updated output close.
Phase 3. Calculate entropy loss

Combined together:

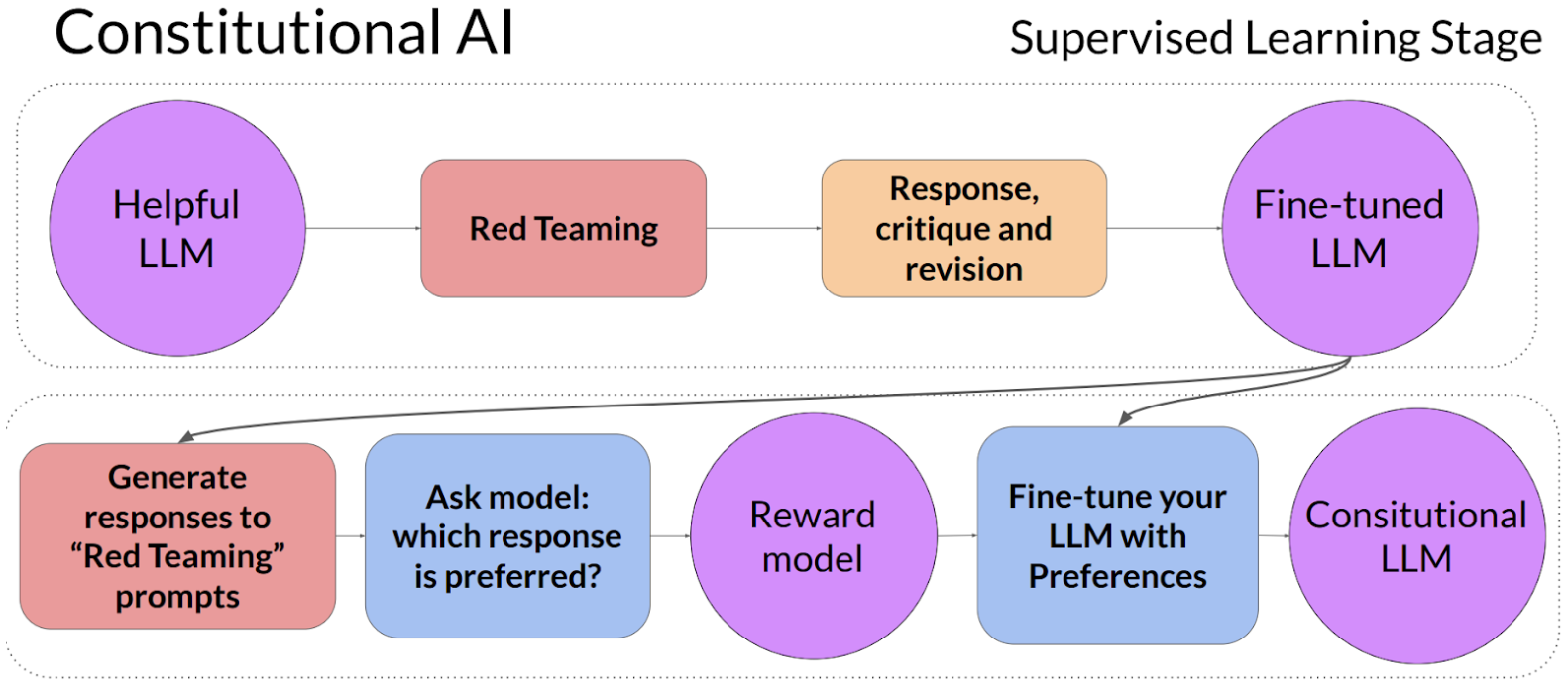
Consitutional AI
- Consitution is a set of prompts describing the principles the model has to follow.
- Read teaming: Human construct prompts that elicits harmful or unwanted responsed.
Reinforcement Learning with AI feedback
LLM Powered Applications
- RAG: Retrieval-augmented generation. Grounding the model on external information. Bard is doing something like this.
- Chain-of-thought planing: Asks the model to show their work. Helps the model deal with more complex math problems.
- Program aided language (PAL) models: Have the LLM generate completions where reasoning steps are accompanied by computer code.
- ReAct: Combining reasoning and action. Shows a LLM through structured examples how to reason through a problem and decide on actions to take.

Leave a comment