Unit 8. Proximal Policy Optimization (PPO)
Introduction
Improves agent’s training stability by avoiding policy updates that are too large by clipping the difference between current and old policy to a specific range ![[1 - \epsilon, 1 + \epsilon]](https://s0.wp.com/latex.php?latex=%5B1+-+%5Cepsilon%2C+1+%2B+%5Cepsilon%5D&bg=ffffff&fg=000&s=0&c=20201002)
Intuition
- Smaller policy updates during training are more likely to converge to an optimal solution.
- Too big update can result in falling “off the clip” and takes a long time or even never recover.
Introducing the Clipped Surrogate Objective Function
Recap: The Policy Objective Function (with A2C)
![L^{PG}(\theta) = E_t[log\pi_\theta(a_t|s_t) A_t]](https://s0.wp.com/latex.php?latex=L%5E%7BPG%7D%28%5Ctheta%29+%3D+E_t%5Blog%5Cpi_%5Ctheta%28a_t%7Cs_t%29+A_t%5D&bg=ffffff&fg=000&s=0&c=20201002)
: Log probability of taking that action at that state.
: Advantage function.
Problems:
- Too small, training process slow.
- Too high, too much variability in training.
PPO’s Clipped Surrogate Objective Function
![L^{CLIP}(\theta) = \hat{E}_t[\min(r_t(\theta)\hat{A}_t, clip(r_t(\theta), 1 - \epsilon, 1 + \epsilon)\hat{A}_t)]](https://s0.wp.com/latex.php?latex=L%5E%7BCLIP%7D%28%5Ctheta%29+%3D+%5Chat%7BE%7D_t%5B%5Cmin%28r_t%28%5Ctheta%29%5Chat%7BA%7D_t%2C+clip%28r_t%28%5Ctheta%29%2C+1+-+%5Cepsilon%2C+1+%2B+%5Cepsilon%29%5Chat%7BA%7D_t%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
The ratio function

- If
, the action
at state $s_t$ is more likely in current.
- If
, less likely.
This ratio can replace the probability we use in the policy objective function.
AKA,
The unclipped part
![L^{CPI}(\theta) = \hat{E_t}[\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\hat{A_t}] = \hat{E_t}[r_t(\theta)\hat{A_t}]](https://s0.wp.com/latex.php?latex=L%5E%7BCPI%7D%28%5Ctheta%29+%3D+%5Chat%7BE_t%7D%5B%5Cfrac%7B%5Cpi_%5Ctheta%28a_t%7Cs_t%29%7D%7B%5Cpi_%7B%5Ctheta_%7Bold%7D%7D%28a_t%7Cs_t%29%7D%5Chat%7BA_t%7D%5D+%3D++%5Chat%7BE_t%7D%5Br_t%28%5Ctheta%29%5Chat%7BA_t%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
To clip the ratio so that we limit the divergence of current policy from the older policy.
- TRPO(Trut Region Policy Optimization) uses KL divergence constraints outside the objective function. Complicated to implement and takes more computation time.
- PPO(Proximal Prolicy Optimization) clips probablility ratio in objective function. Simple.
The clipped objective
![L^{CLIP}(\theta) = \hat{E}_t[min(r_t(\theta)\hat{A}_t, clip(r_t(\theta), 1 - \epsilon, 1 + \epsilon)\hat{A}_t)]](https://s0.wp.com/latex.php?latex=L%5E%7BCLIP%7D%28%5Ctheta%29+%3D+%5Chat%7BE%7D_t%5Bmin%28r_t%28%5Ctheta%29%5Chat%7BA%7D_t%2C+clip%28r_t%28%5Ctheta%29%2C+1+-+%5Cepsilon%2C+1+%2B+%5Cepsilon%29%5Chat%7BA%7D_t%29%5D&bg=ffffff&fg=000&s=0&c=20201002)

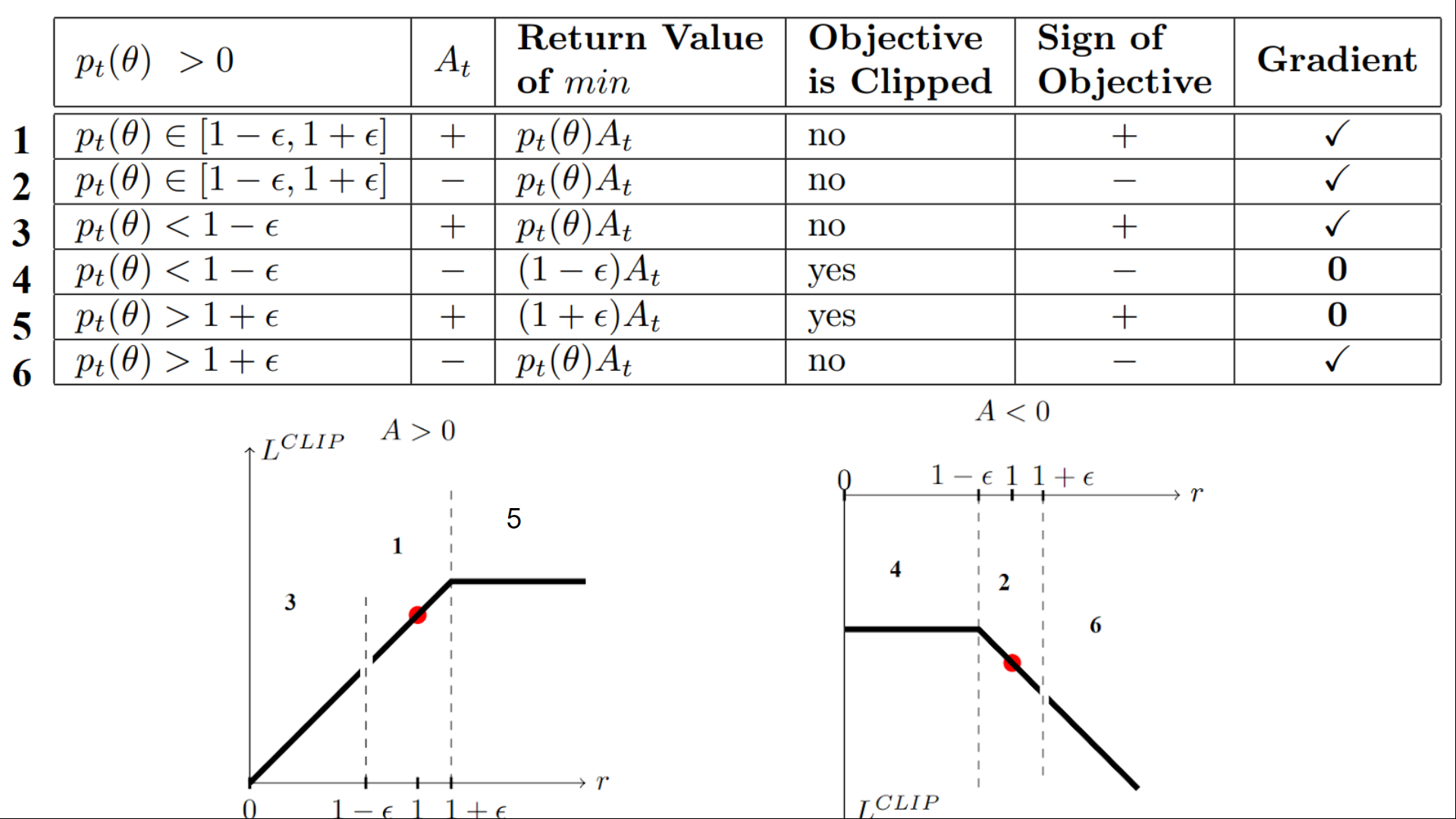
- Unclipped, normal return, normal gradients.
- Clipped, clipped return, no gradient, no updates.
- If
and
, it means we stop aggressively increase a probability of taking the current actition at that state.
- If
and
, it means we stop aggressively decrease a probability of taking the current actition at that state.
- If

Leave a comment